
Please use
the
correct (perma)link to bookmark this article,
not the page
listing all wlog entries of the last decade. Thank you.</update>
Some updates inline and at the bottom.
The
new Terms of Service of GitHub became effective today, which is quite
problematic there was a review phase, but my reviews pointing out the
problems were not answered, and, while the language is somewhat changed
from the draft, they became effective immediately.
Now, the new ToS are not so bad that one immediately must stop using
their service for disagreement, but it s important that certain content
may no longer legally be pushed to GitHub. I ll try to explain
which is affected, and why.
I m mostly working my way
backwards through section D, as
that s where the problems I identified lie, and because this is from
easier to harder.
Note that using a private repository does
not
help, as the same terms apply.
Anything requiring attribution (e.g. CC-BY, but also BSD, )
Section D.7 requires the person uploading content to waive any and all
attribution rights. Ostensibly to allow basic functions like search to
work , which I can even believe, but, for a work the uploader did not
create
completely by themselves, they can t grant this licence.
The CC licences are notably bad because they don t permit sublicencing,
but even so, anything requiring attribution can, in almost all cases, not
written or otherwise, created or uploaded by our Users . This is fact,
and the exceptions are few.
Anything putting conditions on the right to use, display and perform
the work and,
worse, reproduce (all Copyleft)
Section D.5 requires the uploader to grant all other GitHub users
- the right to use, display and perform the work (with no further
restrictions attached to it) while this (likely I didn t check) does
not exclude the GPL, many others (I believe CC-*-SA) are affected, and
- the right to reproduce your Content solely on GitHub as permitted
through GitHub's functionality , with no further restructions attached;
this is a killer for, I believe, any and all licences falling into the
copyleft category.
Note that section D.4 is similar, but granting the licence to GitHub
(and their successors); while this is worded much more friendly than in
the draft, this fact only makes it harder to see if it affects works in
a similar way. But that doesn t matter since D.5 is clear enough. (This
doesn t mean it s not a problem, just that I don t want to go there and
analyse D.4 as D.5 points out the same problems but is easier.)
This means that any and all content under copyleft licences is also
no longer welcome on GitHub.
Anything requiring integrity of the author s source (e.g. LPPL)
Some licences are famous for requiring people to keep the original
intact while permitting patches to be piled on top; this is actually
permissible for Open Source, even though annoying, and the most common
LaTeX licence is rather close to that. Section D.3 says any (partial)
content can be removed though keeping a PKZIP archive of the original
is a likely workaround.
Affected licences
Anything copyleft (GPL, AGPL, LGPL, CC-*-SA) or requiring
attribution (CC-BY-*, but also 4-clause BSD, Apache 2 with NOTICE
text file, ) are affected. BSD-style licences without advertising
clause (MIT/Expat,
MirOS,
etc.) are
probably not affected if GitHub doesn t go too
far and dissociates excerpts from their context and legal info, but
then nobody would be able to distribute it, so that d be useless.
But what if I just fork something under such a licence?
Only continuing to use GitHub constitutes accepting the new terms.
This means that repositories from people who last used GitHub before
March 2017 are excluded.
Even then, the new terms likely only apply to content uploaded in
March 2017 or later (note that git commit dates are unreliable, you
have to actually check whether the contribution dates March 2017 or
later).
And then, most people are likely unaware of the new terms. If they
upload content
they themselves don t have the appropriate
rights (waivers to attribution and copyleft/share-alike clauses), it s
plain illegal and also makes your upload of them or a derivate thereof
no more legal.
Granted, people who, in full knowledge of the new ToS, share any
User-Generated Content with GitHub on or after 1 March, 2017,
and actually have the appropriate rights to do that, can do that;
and if you encounter such a repository, you can fork, modify and
upload that iff you also waive attribution and copyleft/share-alike
rights for your portion of the upload. But especially in the
beginning these will be few and far between (even more so taking
into account that GitHub is, legally spoken, a mess, and they don t
even care about hosting only OSS / Free works).
Conclusion (Fazit)
I ll be starting to remove any such content of mine, such as the
source code mirrors of
jupp, which
is under the GNU GPLv1, now and will be requesting people who forked
such repositories on GitHub to also remove them. This is not something
I like to do but something I am required to do in order to comply with
the licence granted to
me by
my upstream. Anything
you ve found contributed by me in the meantime is up for review; ping
me if I forgot something. (
mksh is
likely safe, even if I hereby remind you that the attribution requirement
of the BSD-style licences still applies outside of GitHub.)
(Pet peeve: why can t I adopt a licence with British spelling?
They
seem to require oversea barbarian spelling.)
The others
Atlassian Bitbucket has similar terms (even worse actually; I looked
at them to see whether I could mirror mksh there, and turns out, I can t
if I don t want to lose most of what few rights I retain when publishing
under a permissive licence). Gitlab seems to not have such, but requires
you to indemnify them YMMV. I think I ll self-host the removed content.
And now?
I m in contact with someone from GitHub Legal (not explicitly in the
official capacity though) and will try to explain the sheer magnitude
of the problem and ways to solve this (leaving the technical issues to
technical solutions and requiring legal solutions only where strictly
necessary), but for now, the ToS are enacted (another point of my
criticism of this move) and thus, the aforementioned works must
go off GitHub
right now.
That s not to say they may not come back later once this all has been
addressed, if it will be addressed to allow that. The new ToS
do
have some good; for example, the old ToS said you allow every GitHub
user to fork your repositories without ever specifying what that means.
It s just that the people over at GitHub need to understand that, both
legally and technically , any and all OSS licences grant enough to run a
hosting platform already , and separate explicit grants are only needed if
a repository contains content not under an OSI/OKFN/Copyfree/FSF/DFSG-free
licence. I have been told that these are important issues and been
thanked for my feedback; we ll see what comes from this.
maybe with a little more effort on the coders side
All licences on
one
of those lists or
conformant to the
DFSG,
OSD or
OKD should do .
e.g. when displaying search results, add a note this is an excerpt,
click HERE to get to the original work in its context, with licence and
attribution where HERE is a backlink to the file in the repository
It is understood those organisations never un-approve any licence
that rightfully conforms to those definitions (also in cases like a grant
saying just use any OSS licence which is occasionally used)
Update: In the meantime, joeyh has written not
one but
two
insightful articles (although I disagree in some details; the new licence
is only to GitHub users (D.5) and GitHub (D.4) and only within their system,
so, while uploaders would violate the ToS (they cannot grant the licence)
and (probably) the upstream-granted copyleft licence, this would
not mean that everyone else wasn t bound by the copyleft licence in, well,
enough cases to count (yes it s possible to construct situations in which
this hurts the copyleft fraction, but no, they re nowhere near 100%).
 Upgrading my solar panels involved switching the house from 12 volts to 24
volts. No reasonably priced charge controllers can handle 1 KW of PV at 12
volts.
There might not be a lot of people who need to do this; entirely 12 volt
offgrid houses are not super common, and most upgrades these days probably
involve rooftop microinverters and so would involve a switch from DC to AC.
I did not find a lot of references online for converting a whole house's
voltage from 12V to 24V.
To prepare, I first checked that all the fuses and breakers were rated for
> 24 volts. (Actually, > 30 volts because it will be 26 volts or so when
charging.) Also, I checked for any shady wiring, and verified that all the
wires I could see in the attic and wiring closet were reasonably sized
(10AWG) and in good shape.
Then I:
Upgrading my solar panels involved switching the house from 12 volts to 24
volts. No reasonably priced charge controllers can handle 1 KW of PV at 12
volts.
There might not be a lot of people who need to do this; entirely 12 volt
offgrid houses are not super common, and most upgrades these days probably
involve rooftop microinverters and so would involve a switch from DC to AC.
I did not find a lot of references online for converting a whole house's
voltage from 12V to 24V.
To prepare, I first checked that all the fuses and breakers were rated for
> 24 volts. (Actually, > 30 volts because it will be 26 volts or so when
charging.) Also, I checked for any shady wiring, and verified that all the
wires I could see in the attic and wiring closet were reasonably sized
(10AWG) and in good shape.
Then I:













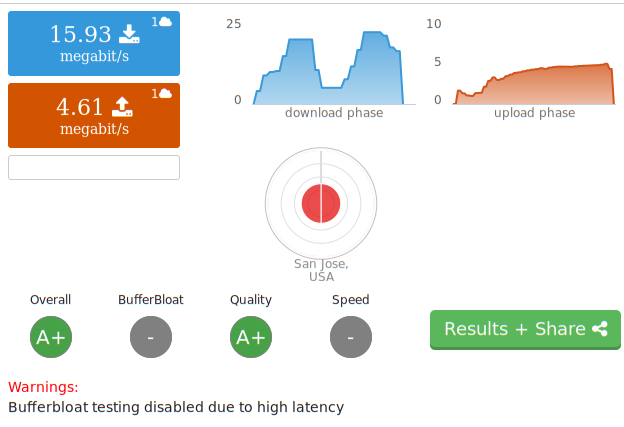

 I woke this morning to
I woke this morning to